本稿では、プロジェクト終了後に発覚する「保守契約の抜け漏れ」と「運用引継ぎ設計の不備」を、実務の現場で起きやすい失敗事例から解きほぐし、打ち手を原理原則とテンプレートで示します。事業会社側のプロジェクトリーダーが、限られた時間と情報の中で意思決定しやすくなるよう、最小限のフレームと話法に絞って、実装できるレベルの具体性で整理しました。
失敗事例:保守契約の抜け漏れと引継ぎ不備
新規サービスのシステム更改プロジェクトが予定通りリリース。開発はきれいに完了したが、運用移行後1か月で障害と問い合わせが急増した。現場は緊急対応に追われ、役員レベルへの日次報告が始まり、PMは疲弊。原因は、保守契約の適用範囲と運用引継ぎの設計が曖昧なままプロジェクトをクローズしてしまったことにあった。
具体的には、アプリのバグは「無償保証」で直してもらえると誤解していたが、契約では受入基準に合格した後の不具合は「軽微バグ」を除き有償。さらに、24/365の監視・一次復旧やバッチ監視は契約対象外で、夜間や休日のアラートは誰も見ていなかった。セキュリティパッチ適用や脆弱性対応も「別見積」の扱いだった。
業務運用の引継ぎも弱かった。運用手順は開発チームのWikiに断片的にあり、正式な運用設計書や復旧手順、SLA/エスカレーションルールが未整備。問い合わせ対応フローとFAQの整備も不足し、コールセンターは回答に迷い、SaaSベンダへの問い合わせ窓口も定まっていなかった。
さらに、インフラはクラウド標準サービスだから大丈夫だろうと過信し、クラウド側の責任分界点(責任共有モデル)を詰めていなかった。OSレベルから上は誰がパッチを当てるのか、監視メトリクスや閾値は誰が決めるのか、バックアップ/リストアの実機検証は誰の責務なのかが空白だった。
コスト面では、保守契約の抜けは「見積もっていない=発生しない」ではなく、「見積もっていない=都度スポット対応で割高」につながった。結果、当初想定のランニングコストを30%超過、さらに障害対応で業務部門の残業も増え、見えないコストが膨らんだ。
この状況でよくある誤反応は、開発ベンダにすべて責任転嫁し「瑕疵だ、無償で直せ」の一点張りになること。しかし、契約・受入証跡・変更管理を精査すると、有償保守や運用設計の不足が原因の部分が多く、交渉は膠着。結果として「プロジェクトは終わったのに終わっていない」状態が長引く。
根本原因を棚卸すと、プロジェクトの出口基準に「運用引継ぎ設計の完了」と「保守契約カバレッジの網羅性」のチェックがなかった。さらに、RACIで責任主体を明確にせず、サービス運営に必要なSLA/OLA/UC(サプライヤとの合意)の接続設計も未実施だった。
教訓は明確だ。開発の完成と、サービスとして運転できる状態は別物である。プロジェクトのゴールは「リリース」ではなく「安定運用の立ち上げ」まで含めるべきであり、保守契約と運用引継ぎを一体で設計しなければ、遅かれ早かれ運用リスクが顕在化する。
原理原則と着目点:運用引継ぎ設計の要諦と視座
第一原則は「サービス視点で分解する」。アプリ開発・インフラ構築・業務運用を縦割りに見るのではなく、ユーザーに提供するサービスの可用性・応答性・セキュリティ・変更容易性という品質特性に対して、誰が何をどこまで担保するかを文書化する。ITILのサービス移行の考え方が有効だ。
第二原則は「3層の契約カバレッジ」を網羅する。プラットフォーム運用(クラウド/ミドル/監視)、アプリケーション保守(改修・不具合対応)、業務運用(問合せ/権限/リリース窓口)の3層で、SLAと責任分界を明確にする。どれか1層でも欠けると、運用の穴が生まれる。
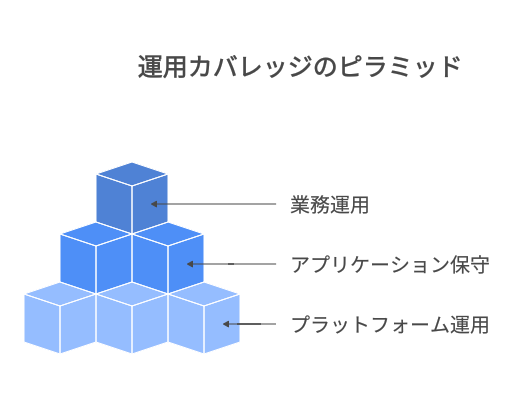
第三原則は「SLA/OLA/UCの接続」。対ユーザーのSLA(サービスレベル)の裏側に、社内の部門間合意(OLA)と、外部サプライヤとの契約(UC)が整合していることが必要。表が3時間の復旧目標を約束するなら、裏側のベンダ契約は2時間以内の一次復旧着手など、整合の取れた設計にする。
第四原則は「RACIで意思決定の迷子をなくす」。障害時の指揮、セキュリティパッチの適用判断、定期メンテナンスの実施、キャパシティ計画の見直しなど、運用における典型的な意思決定点に対して、責任者(R)・承認者(A)・協力者(C)・情報共有(I)を事前に定義する。
第五原則は「フェーズ別出口基準(DoD)」。設計・開発・テスト・本番移行それぞれに、運用観点の完了条件を置く。例えば「本番移行のDoD」に、監視項目と閾値設定完了、復旧手順書リハーサル実施、バックアップからのリストア検証、運用教育とロールプレイ完了を入れる。
第六原則は「運転資格の取得」。自動車で言えば納車と免許は別。運用チームがサービスを安全に運転できるだけの知識・ツール・権限・支援体制が揃って初めて「運転資格あり」。これをチェックリスト化し、未達ならゴー判断をしない。
第七原則は「お金・時間・リスクの三角形を見える化」。24/365の一次対応や厳格なSLAを求めるなら、その分の月額保守費が上がる。逆に費用を抑えるなら、許容できるリスクやユーザーへの告知(カバナンス)をセットで決める。経営判断に耐える材料を揃えることが事業側リーダーの役割。
第八原則は「ハイパーケアからBAUへの段階移行」。リリース後一定期間は開発陣が厚めに伴走(ハイパーケア)し、安定化の指標(インシデント件数、平均復旧時間、変更成功率)が基準を満たしたら定常運用(BAU)に移す。移行条件を数値で握ることで、責任の押し付け合いを防ぐ。
実務テンプレ・話法・RACI等の設計手順
まずは契約カバレッジ表を作る。3層(プラットフォーム/アプリ/業務運用)×項目(監視、一次対応、改修、パッチ、権限、BCP、変更管理、キャパシティ等)で、責任者と契約有無、SLAの有無を塗り分ける。1枚で「穴」を可視化するのが狙い。
| 表:契約カバレッジ(雛形) | 層/項目 | 監視/検知 | 一次対応 | バグ修正 | 変更/小改修 | パッチ/脆弱性 | 権限/アカウント | BCP/バックアップ | 変更管理 | キャパシティ |
|---|---|---|---|---|---|---|---|---|---|---|
| プラットフォーム | ベンダ | ベンダ | 該当無 | 該当無 | ベンダ | 該当無 | ベンダ | ベンダ | ベンダ | ベンダ |
| アプリ | 事業側/ベンダ | ベンダ | ベンダ | ベンダ | 事業側/ベンダ | 該当無 | 事業側 | 事業側/ベンダ | 事業側 | ベンダ |
| 業務運用 | 事業側 | 事業側 | 該当無 | 該当無 | 該当無 | 事業側 | 事業側 | 事業側 | 事業側 | 事業側 |
注:セルに「誰が」「契約/内製/未定」を具体記載し、SLA値(例:着手30分、復旧4時間)を付与する。
次にRACIを定める。障害対応、定期メンテ、リリース判定、重大変更の承認などの主要イベントを列挙して、各ロール(事業責任者、運用リーダー、開発ベンダPM、SaaSサポート、セキュリティ、クラウド運用)に割り当てる。Aは一人に絞る。
| 表:RACI(抜粋) | 事項 | 事業責任者 | 運用リーダー | 開発ベンダPM | クラウド運用 | セキュリティ |
|---|---|---|---|---|---|---|
| 障害宣言/コミュニケーション | I | R | C | C | I | C |
| 重大障害の復旧方針 | A | R | C | C | C | I |
| 定期パッチ適用判断 | A | R | C | R | C | C |
| 本番リリース可否 | A | R | C | C | C | C |
| キャパ増強判断 | A | R | C | R | I | I |
運用引継ぎ計画テンプレは、章立てを固定する。1) サービス概要/品質目標(SLA) 2) 組織・RACI 3) 手順書/Runbook(監視、復旧、デプロイ、権限) 4) 台帳(構成CI、契約、連絡網) 5) セキュリティ(脆弱性、鍵/証明書、ログ保全) 6) 変更/リリース管理 7) BCP/バックアップ/演習 8) KPI/レポート 9) ハイパーケア計画 10) 受入判定基準。
受入判定(運用準備レビュー)のチェックリストも固定化する。例えば、(a) 監視項目/閾値/通知経路の定義済 (b) 復旧手順のドライラン完了 (c) バックアップ/リストアの実機検証完了 (d) アクセス権限の申請/付与フロー整備 (e) 重大障害コミュニケーション雛形用意 (f) KPIダッシュボード雛形構築 (g) ベンダ契約のSLA整合確認 (h) 連絡網・エスカレーション動作確認。
話法(上層部向け)は「投資対効果とリスクの見える化」に絞る。例:「SLAを4時間→2時間に上げるには月額+200万円、インシデント時の売上逸失を1回あたり300万円と見積もると、年間3回以上の障害を防げば投資回収できます」。数字で意思決定を促す。
話法(ベンダ交渉)は「契約と運用成果の両立」を軸にする。例:「SLA整合のため、一次対応の着手時間を30分に短縮したい。その代わり定型作業の自動化を進め、総工数は相殺します」。譲り合いの余地を用意しつつ、期待成果を明確化する。
最後に「タイムライン設計」。リリースT-60日で運用準備レビュー1回目(ギャップ洗出し)、T-30日で2回目(是正確認)、T-7日で最終判定。T+0〜T+30でハイパーケア、T+30でBAU移行判定会。会議体と意思決定者を事前に確定する。
テンプレの保管先は、運用の実務者がアクセスしやすい場所に限定する。プロジェクト用資料庫と運用用ナレッジを分け、Runbookは運用側のリポジトリを正本とする。変更が生じたらリリースチケットと一体で差分管理する。
失敗事例への当てはめ:契約と運用の再設計例
まず、現状の契約カバレッジ表を作成し「穴」を特定した。結果、夜間一次対応、セキュリティパッチ、バッチ監視、問い合わせフロー、バックアップ演習の5点が未契約・未整備と判明。優先度を付け、顧客影響と発生確率で並べ替えた。
契約面では、アプリ保守に「インシデント対応SLA(着手30分/復旧4時間目標)」を追加したAMS契約を締結。プラットフォームは監視・一次復旧を含む運用SOWをベンダと別建てで結び、責任分界(IaaSはベンダ、OS以上は当社/開発ベンダ)を明文化した。セキュリティパッチは四半期適用の定例化と、重大脆弱性は例外フローを用意。
業務運用は、問い合わせ一次受けをカスタマーサポートへ移管し、FAQ/ナレッジを共同整備。SaaS/外部APIの障害時は、サプライヤにエスカレーションするUC(Underpinning Contract)を更新し、相手方SLA(ステータス更新頻度・復旧目標)を明示させた。
SLA/OLAの接続では、ユーザー向けSLAを「重要機能の復旧目標4時間、問い合わせ初動30分、定期メンテは毎月第2金曜深夜」に定義。これに合わせて、社内OLAは運用→開発のエスカレーション着手15分、決定者は運用リーダー、重大判断は事業責任者に設定。ベンダ契約は相応の着手・復旧目標に引き上げた。
RACIは、重大障害の指揮(A)を事業責任者に一本化、技術的リード(R)を運用リーダーに、コミュニケーションは広報と連携(C)に再整理。定期パッチの判断(A)と保留のリスク承認(A)を同一人物に集約し、判断の拡散を防止。連絡網はワンコールで集まるブリッジ番号を固定。
運用引継ぎは、Runbookをゼロから書き直し、バッチ監視と手当の手順、再実行コマンド、依存先の確認項目を具体化。復旧手順は実機でドライランし、録画・記録を残してオンボーディング教材に転用。バックアップは月次でリストア演習を行い、復旧時間をKPI化した。
ハイパーケアは30日間、開発チームが平日日中は常駐、夜間はオンコール。KPIとして、平均復旧時間(MTTR)、重大インシデント件数、変更成功率、一次回答時間を週次レビュー。目標達成でBAUに移行し、保守費のレートもハイパーケアから平常に切替える条項を契約に盛り込んだ。
結果、障害の平均復旧時間は8時間から2.5時間へ短縮。問い合わせ一次回答は3時間から20分へ改善。スポット対応費は月100万円超から、定額保守内でほぼ吸収。上層部への緊急報告はゼロになり、チームの負荷と心理的安全性も回復した。以後の案件は、本稿のテンプレを標準として横展開し、同様の抜け漏れを未然防止できている。
運用は「納品物」ではなく「継続する経営能力」です。開発の成功と安定運用の成功は別レースであり、契約と引継ぎ設計をワンセットで早期に設計することが、事業側リーダーの最大のリスク対策になります。まずは、契約カバレッジ表とRACIを1枚で描き、運用準備レビューをT-60日から回す。今日、あなたのプロジェクトの「穴」は1時間で見つけられます。明日からの混乱を、今日の1時間で止めましょう。
参考リンク(公式/信頼できる情報源)
- PMI(Project Management Institute): https://www.pmi.org
- PeopleCert(ITIL 4 / 旧AXELOS): https://www.peoplecert.org
- ISACA(COBIT): https://www.isaca.org
- IPA 独立行政法人情報処理推進機構: https://www.ipa.go.jp
- デジタル庁: https://www.digital.go.jp
- AWS 共有責任モデル(責任分界の参考): https://aws.amazon.com/jp/compliance/shared-responsibility-model/

コメント